从0开始学AI情感语音,科哥打造的IndexTTS2超简单上手
本文介绍了基于星图GPU平台自动化部署indextts2-IndexTTS2 最新 V23版本的全面升级情感控制更好 构建by科哥镜像的方法,助力用户快速搭建AI情感语音合成环境。该镜像支持通过WebUI或API实现高自然度的情感化语音生成,适用于内容创作、虚拟主播、有声书制作等场景,显著提升AI语音的表现力与个性化水平。
从0开始学AI情感语音,科哥打造的IndexTTS2超简单上手
1. 引言:让AI声音真正“有感情”
在内容创作、在线教育、智能客服等场景中,语音合成技术(TTS)正变得无处不在。然而,大多数系统仍停留在“能说”的阶段——发音清晰但语气生硬,缺乏真实人类说话时的情感起伏与语调变化。
如何让AI不仅“会读”,还能“会表达”?这是当前语音合成领域的核心挑战。而IndexTTS2最新V23版本的发布,正是朝着这一目标迈出的关键一步。由开发者“科哥”主导构建,该版本实现了情感控制能力的全面升级,通过上下文感知建模和参考音频驱动机制,显著提升了语音的情感自然度与个性化表现力。
更重要的是,项目提供了极简化的使用流程和图形化界面,使得即使是零代码背景的内容创作者,也能快速生成带有细腻情绪色彩的语音内容。本文将带你从零开始,完整掌握IndexTTS2的部署、使用与优化技巧。
2. 系统架构与核心技术解析
2.1 整体运行架构
IndexTTS2采用模块化设计,整体结构清晰且易于本地部署:
[用户操作]
↓
[WebUI前端界面] ←→ [Gradio后端服务]
↓
[IndexTTS2推理引擎]
↓
[预训练模型 & 缓存管理]
↓
[音频输出文件]
所有组件均运行于本地主机,保障数据隐私安全。默认监听 localhost:7860,防止外部未授权访问。
2.2 情感建模机制深度拆解
传统TTS的情感处理多为后期音调调节,属于“贴标签式”增强,容易导致语义断裂或夸张失真。IndexTTS2 V23则引入了上下文感知的情感融合架构,其工作流程如下:
- 文本编码阶段:输入文本经过分词、音素转换与语义嵌入,生成语言特征向量;
- 情感注入阶段:选定的情感类型(如“鼓励”、“担忧”)被编码为高维情感向量,并通过注意力机制与语言特征深度融合;
- 声学生成阶段:融合后的表示送入基于Transformer或Diffusion的声学模型,生成带情感倾向的梅尔频谱图;
- 波形还原阶段:由HiFi-GAN类神经声码器将频谱图还原为高质量音频波形。
这种端到端联合训练的方式,使模型在训练过程中就学习到了不同情绪下韵律模式、停顿分布、重音位置的内在规律,从而实现更连贯、自然的情感表达。
示例对比:
同一句话:“你做得很好”,在不同情感参数下的听觉效果差异明显: - emotion="praise":热情洋溢,语调上扬,节奏轻快; - emotion="reassure":温和低沉,语速平稳,带有抚慰感; - emotion="sarcasm"(若支持):轻微拖长尾音,配合音高波动,透出反讽意味。
这些差异并非后期加工,而是模型对情感语用规则的理解体现。
2.3 参考音频驱动的情感迁移
V23版本新增的核心功能之一是参考音频驱动的情感迁移。用户可上传一段目标说话人的语音片段(如主播访谈录音),系统自动提取其中的语调曲线、节奏特征与情感风格,并将其迁移到新文本的合成过程中。
这相当于实现了“克隆式情感复现”——即使原声者从未说过这句话,AI也能模仿出他/她特有的语气风格。对于虚拟偶像、有声书角色配音等需要保持声音一致性的场景,具有极高实用价值。
3. 快速上手:从启动到生成第一条情感语音
3.1 环境准备与前置要求
在开始前,请确保满足以下条件:
| 项目 | 推荐配置 |
|---|---|
| 内存 | ≥ 8GB(建议16GB以上用于CPU推理) |
| 显存 | ≥ 4GB GPU(NVIDIA CUDA兼容) |
| 存储空间 | ≥ 10GB(含模型缓存) |
| 网络环境 | 稳定连接(首次需下载大模型文件) |
注意:模型文件存储于
cache_hub/目录,请勿删除,否则每次启动都将重新下载。
3.2 启动WebUI服务
进入项目目录并执行启动脚本:
cd /root/index-tts && bash start_app.sh
该命令会自动完成以下操作: - 初始化Python环境依赖 - 加载预训练模型(首次运行需联网下载) - 启动Gradio Web服务
启动成功后,浏览器访问 http://localhost:7860 即可进入操作界面。
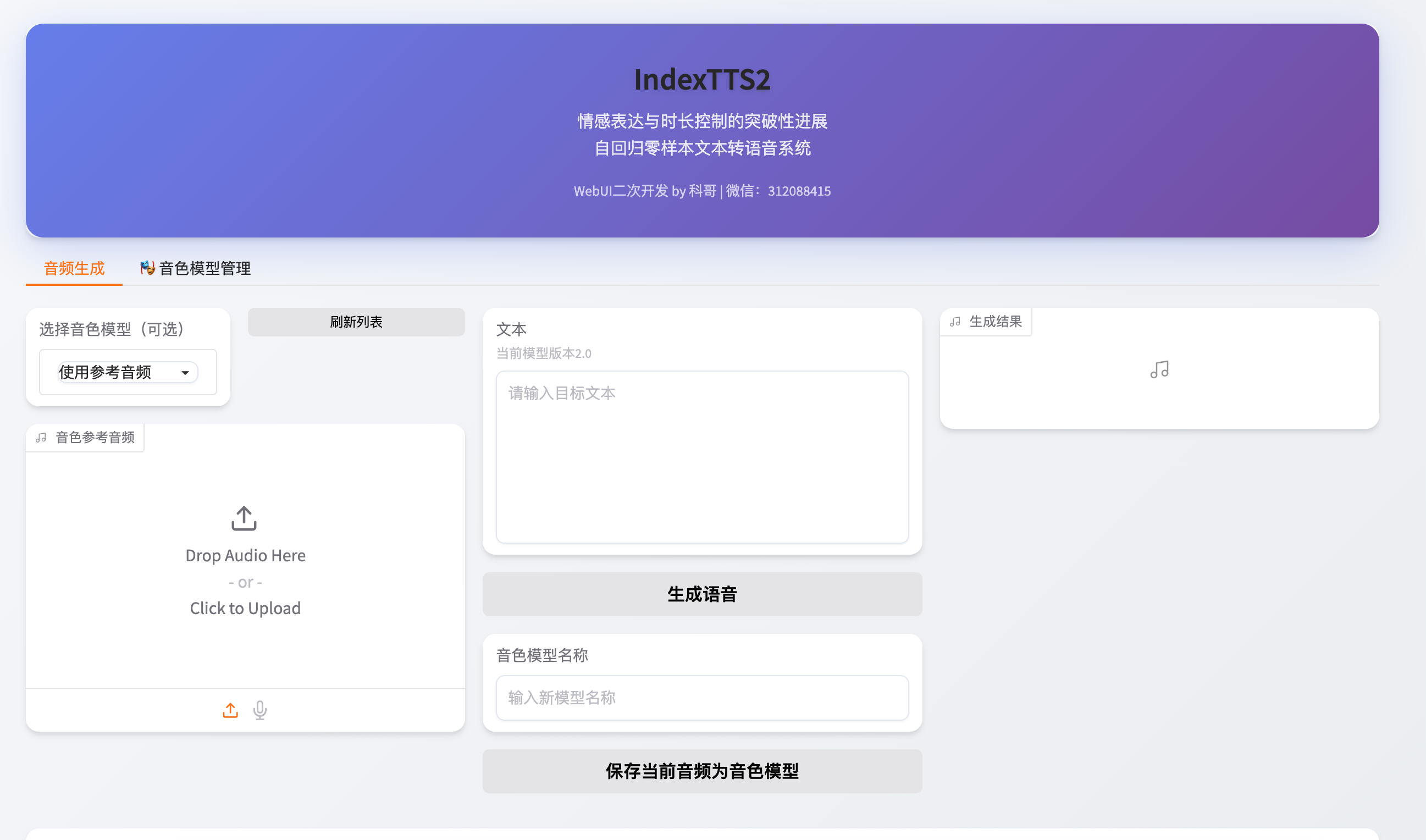
3.3 使用WebUI生成情感语音
界面主要包含以下几个功能区:
- 文本输入框:支持中文、英文混合输入;
- 情感选择下拉菜单:提供多种预设情感类型(如高兴、悲伤、鼓励、严肃等);
- 强度滑动条:调节情感表达的浓烈程度(0.0 ~ 1.0);
- 语速/音高微调滑块:精细控制输出语音节奏;
- 参考音频上传区:支持上传
.wav或.mp3文件以启用情感迁移; - 批量处理功能:可导入文本列表,一键生成多段音频并打包下载。
实操步骤示例:
- 输入文本:“今天的天气真不错。”
- 选择情感类型:
happy - 设置情感强度:0.8
- 调整语速至 1.1x,音高 +3 半音
- (可选)上传一段轻松语调的参考音频
- 点击“合成”按钮,等待几秒即可播放结果
你可以反复调整参数,实时预览效果,直到获得满意的声音表现。
4. 高级功能与工程实践建议
4.1 批量语音生成与自动化导出
对于需要制作大量语音内容的场景(如电子书朗读、短视频配音),可使用批量处理模式:
- 准备一个纯文本文件(
.txt),每行一条待合成语句; - 在WebUI中点击“批量导入”按钮上传该文件;
- 统一设置情感、强度等公共参数;
- 系统将逐条合成并生成编号音频文件(如
output_001.wav,output_002.wav); - 完成后支持一键打包下载ZIP文件。
此功能极大提升内容生产效率,适合团队协作或规模化应用。
4.2 API调用方式(适用于开发者)
虽然完整代码未开源,但从启动逻辑可推测其内部API结构。假设存在Python接口,典型调用方式如下:
# 伪代码示例:IndexTTS2推理调用
audio = model.synthesize(
text="这次没能赢,但我们会继续努力",
emotion="regret", # 情感标签
intensity=0.6, # 情感强度
speed=0.95, # 语速微调
pitch_shift=2, # 音高偏移(单位:半音)
reference_audio="sample.wav" # 参考音频路径
)
未来若开放RESTful API,可通过HTTP请求实现远程集成,适用于智能客服、互动游戏等动态场景。
4.3 性能优化与资源管理
GPU加速建议:
- 使用NVIDIA显卡(CUDA 11.8+)
- 显存≥4GB,推荐RTX 3060及以上型号
- 开启混合精度推理(FP16)以提升速度
CPU推理注意事项:
- 内存≥16GB,避免OOM崩溃
- 合成时间约为GPU的3~5倍(实测30秒语音约需12~18秒)
- 建议关闭其他内存密集型程序
缓存管理:
- 模型缓存位于
/root/index-tts/cache_hub/ - 首次运行后无需重复下载,可离线使用
- 若更换设备,可手动复制该目录以节省带宽
5. 注意事项与合规提醒
5.1 首次运行常见问题
- 网络不稳定导致下载中断:建议使用稳定宽带环境,必要时可尝试断点续传工具辅助。
- 权限不足无法写入缓存目录:确保当前用户对
cache_hub/有读写权限。 - 端口占用冲突:若7860端口已被占用,可在启动脚本中修改监听端口。
5.2 版权与法律风险提示
- 参考音频必须合法授权:未经授权使用他人声音进行克隆可能侵犯人格权与肖像权;
- 禁止用于虚假信息传播:不得利用该技术伪造名人发言、制造谣言;
- 商业用途需确认许可范围:部分预训练模型可能存在使用限制,请查阅官方文档。
项目方已在文档中明确提醒用户遵守相关法律法规,体现了负责任的技术伦理态度。
5.3 安全性建议
- 默认仅绑定
localhost,防止外网访问; - 如需远程协作,应通过Nginx反向代理 + HTTPS加密 + 身份认证机制实现;
- 定期更新系统补丁,防范潜在漏洞。
6. 技术支持与生态建设
IndexTTS2不仅仅是一个工具,更在逐步构建一个围绕情感语音的技术生态:
- GitHub仓库:https://github.com/index-tts/index-tts 提供源码结构说明与开发进展
- Issues反馈渠道:用于提交Bug报告或功能建议
- 微信技术支持:科哥个人技术号 312088415,提供一对一答疑(添加时请备注“IndexTTS”)
这种“产品 + 服务 + 社区”的闭环模式,显著降低了用户的使用门槛,也增强了项目的可持续发展能力。
7. 总结
IndexTTS2 V23版本的推出,标志着中文情感语音合成技术迈入了一个新阶段。它不仅在底层实现了上下文感知的情感建模与参考音频驱动的风格迁移,更通过简洁直观的WebUI设计,将高阶能力转化为普通人也能轻松使用的生产力工具。
无论是内容创作者希望为视频增添情绪张力,还是开发者想打造更具人性化的AI助手,这套系统都提供了稳定、高效且可定制的解决方案。
随着未来对更多细粒度情感维度(如“犹豫”、“讽刺”、“俏皮”)的支持,以及多语言、多方言能力的拓展,IndexTTS有望成为中文TTS领域的重要标杆。
当机器开始理解“语气背后的潜台词”,我们距离真正的拟人化交互,已经不远。
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

网易智企-云信开发者社区是面向全网开发者的技术交流与服务平台,依托近 29 年 IM、音视频技术积累,提供 IM、RTC、实时对话智能体、云原生、短信等全场景开发资源。
更多推荐

 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)